Designing Machine Learning Systems: An Iterative Process for Production-Ready Applications
Introduction
Machine learning (ML) has become an integral part of modern applications, enabling them to learn from data and improve their performance over time. However, building a production-ready ML system requires a systematic and iterative approach that considers various factors, including data quality, model selection, evaluation, and deployment. This white paper outlines a structured process for designing ML systems, emphasizing the importance of iteration and continuous improvement.
Understanding the Problem
-
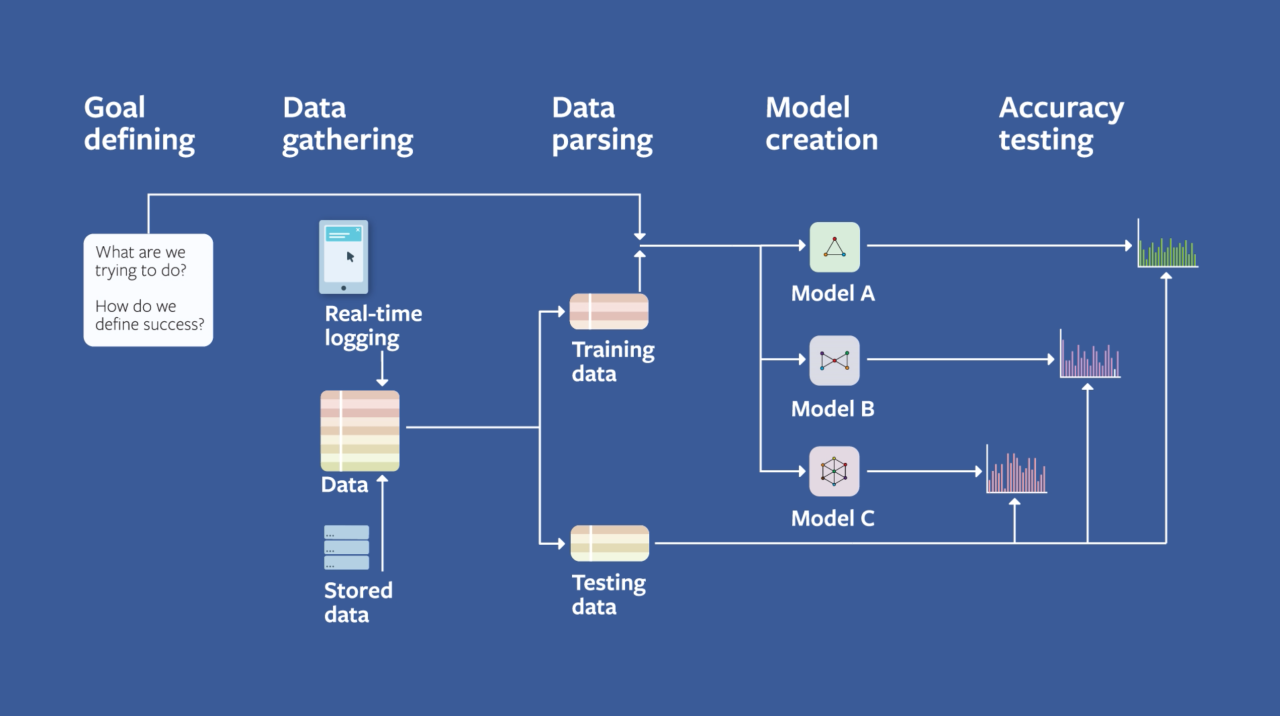
Problem Definition: Clearly define the problem that the ML system aims to solve. Identify the key objectives, constraints, and performance metrics.
-
Data Availability and Quality: Assess the availability and quality of the data required for training and testing the model. Consider factors such as data volume, diversity, and relevance.
Data Collection and Preparation
-
Data Acquisition: Gather relevant data from various sources, ensuring compliance with privacy regulations and ethical guidelines.
-
Data Cleaning and Preprocessing: Clean the data to remove inconsistencies, errors, and missing values. Perform necessary transformations, such as normalization and feature engineering, to prepare the data for modeling.
Feature Engineering
-
Feature Selection: Identify the most informative features that contribute significantly to the model's performance. Use techniques like correlation analysis, feature importance, and dimensionality reduction.
-
Feature Creation: Engineer new features that capture relevant patterns or relationships within the data. This can involve combining existing features or creating derived features.
Model Selection and Training
-
Algorithm Selection: Choose appropriate ML algorithms based on the problem type (e.g., classification, regression, clustering) and the characteristics of the data.
-
Model Training: Train the selected models using the prepared dataset, optimizing hyperparameters to achieve the best performance.
-
Model Evaluation: Evaluate the trained models using appropriate metrics (e.g., accuracy, precision, recall, F1-score) on a validation dataset to assess their generalization ability.
Model Improvement and Tuning
-
Hyperparameter Tuning: Fine-tune the model's hyperparameters to optimize performance. Consider techniques like grid search, random search, or Bayesian optimization.
-
Ensemble Methods: Combine multiple models to improve predictive power and reduce overfitting. Explore techniques like bagging, boosting, and stacking.
-
Regularization: Prevent overfitting by introducing penalties for complex models. Use techniques like L1 and L2 regularization.
Model Deployment and Monitoring
-
Deployment: Integrate the trained model into the production environment, ensuring compatibility with the application's infrastructure and scalability requirements.
-
Monitoring: Continuously monitor the model's performance in production, tracking metrics like prediction accuracy, latency, and resource utilization.
-
Retraining and Updating: Regularly retrain the model with new data to maintain its effectiveness and adapt to changing conditions.
Iterative Process
The process of designing ML systems is inherently iterative. As new data becomes available or insights are gained, the model can be refined and improved. This iterative approach allows for continuous learning and adaptation, ensuring that the ML system remains effective and aligned with evolving business needs.
Conclusion
Designing and deploying production-ready ML systems requires a structured and iterative approach. By following the steps outlined in this white paper, organizations can build robust and effective ML applications that drive value and innovation.
References
General Machine Learning References:
-
Géron, A. (2019). Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques for Building Intelligent Systems. O'Reilly Media.
-
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
-
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer.
Data Preprocessing and Feature Engineering:
-
Alpaydin, E. (2014). Introduction to Machine Learning (3rd ed.). MIT Press.
-
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An Introduction to Statistical Learning: with Applications in R. Springer.
Model Selection and Evaluation:
-
Kohavi, R., & Provost, F. (2000). Glossary of terms for the evaluation of classification models. Knowledge and Information Systems, 1(1), 31-41.
-
Mitchell, T. M. (1997). Machine Learning. McGraw-Hill.
Model Deployment and Monitoring:
-
Breck, E., Chambers, D., & Sculley, D. (2015). The machine learning workflow at Google: A look at the process, tools, and infrastructure. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 157-166). ACM.
-
Sculley, D., Ghahramani, Z., Hinton, G., & Weinberger, K. Q. (2015). Hidden unit modeling: A framework for modeling and understanding neural networks. In Advances in Neural Information Processing Systems (pp. 4409-4417).
Note: Please please contact ias-research.com